|
文章目录
像素级分类指标1.MIOU2.IOU3.F14.Kappa5. Acc6. Recall7. 虚警率8. 漏提率
基于对象的指标基于边缘的指标
像素级分类指标
1.MIOU
mIoU可解释为平均交并比,即在每个类别上计算IoU值(即真正样本数量/(真正样本数量+假负样本数量+假正样本数量))。
import numpy as np
import glob
import tqdm
from PIL import Image
import cv2 as cv
import os
from sklearn.metrics import confusion_matrix,cohen_kappa_score
from skimage import io
from skimage import measure
from scipy import ndimage
from sklearn.metrics import f1_score
def mean_iou(input, target, classes = 2):
""" compute the value of mean iou
:param input: 2d array, int, prediction
:param target: 2d array, int, ground truth
:param classes: int, the number of class
:return:
miou: float, the value of miou
"""
miou = 0
for i in range(classes):
intersection = np.logical_and(target == i, input == i)
# print(intersection.any())
union = np.logical_or(target == i, input == i)
temp = np.sum(intersection) / np.sum(union)
miou += temp
return miou/classes
2.IOU
IoU (Intersection over Union) 从字面意义上来说就是交并比,顾名思义就是两个集合的交集与两个集合的并集之比。
def iou(input, target, classes=1):
""" compute the value of iou
:param input: 2d array, int, prediction
:param target: 2d array, int, ground truth
:param classes: int, the number of class
:return:
iou: float, the value of iou
"""
intersection = np.logical_and(target == classes, input == classes)
# print(intersection.any())
union = np.logical_or(target == classes, input == classes)
iou = np.sum(intersection) / np.sum(union)
return iou
3.F1
F1分数(F1 Score),是统计学中用来衡量二分类模型精确度的一种指标。它同时兼顾了分类模型的精确率和召回率。F1分数可以看作是模型精确率和召回率的一种调和平均,它的最大值是1,最小值是0。
def compute_f1(prediction, target):
"""
:param prediction: 2d array, int,
estimated targets as returned by a classifier
:param target: 2d array, int,
ground truth
:return:
f1: float
"""
prediction.tolist(), target.tolist()
img, target = np.array(prediction).flatten(), np.array(target).flatten()
f1 = f1_score(y_true=target, y_pred=img)
return f1
4.Kappa
Kappa系数用于一致性检验,也可以用于衡量分类精度,但kappa系数的计算是基于混淆矩阵的。
def compute_kappa(prediction, target):
"""
:param prediction: 2d array, int,
estimated targets as returned by a classifier
:param target: 2d array, int,
ground truth
:return:
kappa: float
"""
prediction.tolist(), target.tolist()
img, target = np.array(prediction).flatten(), np.array(target).flatten()
kappa = cohen_kappa_score(target, img)
return kappa
5. Acc
基于混淆矩阵实现,混淆矩阵的对角线之和除以该矩阵的元素和。
def compute_acc(gt, pred):
matrix = confusion_matrix(y_true=np.array(gt).flatten(), y_pred=np.array(pred).flatten())
acc = np.diag(matrix).sum() / matrix.sum()
return acc
6. Recall
召回率(Recall)就是被分为正类的样本数与测试数据集中的实际正类的样本数之比,意味着应该被分为正类的样本中会有多少是被正确分类出来,如下式所示: 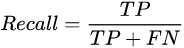
def compute_recall(gt, pred):
# 返回所有类别的召回率recall
matrix = confusion_matrix(y_true=np.array(gt).flatten(), y_pred=np.array(pred).flatten())
recall = np.diag(matrix) / matrix.sum(axis = 0)
return recall
7. 虚警率
FPR = FP / (TN+FP)
8. 漏提率
FNR = FN / (TP+FN)
基于对象的指标
paper: Adversarial Shape Learning for Building Extraction in VHR Remote Sensing Images
虽然基于像素的评价指标呈现了结果的总体分类精度,但它们没有考虑到分割单元[47]的主题和几何特性。为了克服这一限制,我们设计了三个基于对象的评估度量,包括匹配率(Mr)、曲率误差(Ecurv)和形状误差(Eshape)。这些指标是文献作品[51],[48]的变体,以适应对建筑提取结果的评估。
为了比较预测图P上的分割对象Sj和GT图L上的参考对象Oi的几何质量,必须首先要区分它们是否代表相同的物理对象。对于每个Oi(i=1、2、3、··、n)和Sj(j=1、2、3、··、n0),基于过分割误差(Eos)和过分割误差(Eus)[51]计算它们的匹配关系M(Oi、Sj):
 shape_eval.py shape_eval.py
import os
import cv2
import time
import numpy as np
from skimage import io, measure
from skimage.color import label2rgb
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self):
self.initialized = False
self.val = None
self.avg = None
self.sum = None
self.count = None
def initialize(self, val, count, weight):
self.val = val
self.avg = val
self.count = count
self.sum = val * weight
self.initialized = True
def update(self, val, count=1, weight=1):
if not self.initialized:
self.initialize(val, count, weight)
else:
self.add(val, count, weight)
def add(self, val, count, weight):
self.val = val
self.count += count
self.sum += val * weight
self.avg = self.sum / self.count
def value(self):
return self.val
def average(self):
return self.avg
# input: binary image
def bn_region_growing(img, seed, region_limit=False, return_range=True):
# print('region grow at seed: [%d, %d]'%(seed[0], seed[1]))
# Parameters for region growing
neighbors = [(-1, 0), (1, 0), (0, -1), (0, 1)]
# Input image parameters
h, w = img.shape
# Initialize segmented output image
segmented_obj = np.zeros((h, w), np.uint8)
loc_range = [seed[0], seed[0], seed[1], seed[1]]
seed_list = [seed]
segmented_obj[seed[0], seed[1]] = 1
# Region growing until ...
perimeter = 0
while len(seed_list):
if region_limit:
if np.sum(segmented_obj) > region_limit: break
check_seed = seed_list.pop(0)
# boundary_mark = False
for offsets in neighbors:
n_x = check_seed[0] + offsets[0]
n_y = check_seed[1] + offsets[1]
if n_x = h or n_y = w: continue
# if not img[n_x, n_y]: boundary_mark = True
if img[n_x, n_y] and segmented_obj[n_x, n_y] == 0:
segmented_obj[n_x, n_y] = 1
seed_list.append([n_x, n_y])
if return_range:
if n_x loc_range[1]: loc_range[1] = n_x
if n_y loc_range[3]: loc_range[3] = n_y
# if boundary_mark: perimeter+=1
# print('object area: %d, perimeter: %d.'%(np.sum(segmented_obj), perimeter))
# io.imsave('/home/dinglei/Code/BSeg_pred/binary/obj%d%d.png'%(seed[0], seed[1]), segmented_obj*255)
if return_range:
return segmented_obj, loc_range
else:
return segmented_obj
def get_chain_code(boundary):
current = boundary[-1][0]
chain = []
for i in boundary:
i = i[0]
dx = i[0] - current[0]
dy = i[1] - current[1]
if dx 0:
chain.append(6)
if dx 0:
chain.append(7)
current = i
return chain
def calc_curvature(chain):
curvature = 0
current = chain[-1]
for i in chain:
dif = np.abs(i - current)
assert dif 4: dif = 8 - dif
curvature += dif
return curvature
def mark_img(img, bn_thred=0):
img = (img > bn_thred).astype(np.uint8)
if img.ndim > 2: img = img[:, :, 0]
h, w = img.shape
# Parameters for region growing
img_index = np.zeros((h, w)).astype(np.uint64)
objects = []
obj_id = 0
for i in range(h):
for j in range(w):
if img[i, j] > 0 and img_index[i, j] == 0:
segmented_obj, loc_range = bn_region_growing(img, [i, j])
obj_id += 1
img = img - segmented_obj
img_index += segmented_obj * obj_id
obj = seg_object(obj_id, segmented_obj, loc_range)
if obj.area > 15: objects.append(obj)
print('Index image generated. Num_objects: %d' % len(objects))
# rgb_map = label2rgb(img_index)
return img_index, objects
class seg_object(object):
def __init__(self, index, segmented_map, loc_range):
self.idx = index
self.loc_range = loc_range
self.area = np.sum(segmented_map)
if self.area 1:
for i in range(1, len(contours)): self.perimeter += cv2.arcLength(contours[i], True)
# self.perimeter = measure.perimeter(segmented_map, neighbourhood=4)
if not self.perimeter: self.perimeter = 0.01
p_eac = np.sqrt(self.area * np.pi) * 2
self.compact = p_eac / self.perimeter
def get_map(self, index_map):
return (index_map == self.idx).astype(np.uint8)
def shape_eval(GT_img, pred_img):
start = time.time()
index_GT_map, objects_GT = mark_img(GT_img, bn_thred=127)
index_pred_map, objects_pred = mark_img(pred_img, bn_thred=127)
thred_overseg = 0.7
thred_underseg = 0.7
num_match = 0
compact_meter = AverageMeter()
curve_meter = AverageMeter()
for item_GT in objects_GT:
GT_item_map = item_GT.get_map(index_GT_map)
h0, h1, w0, w1 = item_GT.loc_range
# area_match_thred = [int(item_GT.area*0.7), int(item_GT.area*1.3)]
for item_pred in objects_pred:
u0, u1, v0, v1 = item_pred.loc_range
outbound = False
if u0 > h1 or u1 w1 or v1 thred_underseg and r_overseg > thred_overseg:
num_match += 1
compact_error = np.abs(item_GT.compact - item_pred.compact)
curve_error = np.abs(item_GT.curv - item_pred.curv)
compact_meter.update(compact_error)
curve_meter.update(curve_error)
# print('match item found. compact error: %.2f'%compact_error)
continue
match_ratio = num_match / len(objects_GT)
print('Running time: %.2f match items: %d. Match rate: %.2f, mean compact error: %.2f curv error: %.2f.' \
% (time.time() - start, num_match, match_ratio * 100, compact_meter.avg * 100, curve_meter.avg * 100))
return match_ratio, compact_meter.avg, curve_meter.avg
if __name__ == '__main__':
import gdalTools
import pandas as pd
import glob
import tqdm
outPath = "ObjectEval.xlsx"
if os.path.exists(outPath):
os.remove(outPath)
names = []
matchs = []
compacts = []
curves = []
gtPath = r'D:\MyWorkSpace\paper\fishpond\data_evaluation\test2\poly.tif'
predList = glob.glob("./*/*/poly.tif")
for predictPath in tqdm.tqdm(predList):
name = predictPath.split("\\")[-2]
im_proj, im_geotrans, im_width, im_height, gt = gdalTools.read_img(gtPath)
im_proj, im_geotrans, im_width, im_height, pred = gdalTools.read_img(predictPath)
GT_img = np.where(gt > 0, 255, 0)
pred_img = np.where(pred > 0, 255, 0)
match_ratio, mcompact_error, mcurve_error = shape_eval(GT_img, pred_img)
print('Average match rate: %.2f, avg compact error: %.2f, avg curv error: %.2f' % (
match_ratio * 100, mcompact_error * 100, mcurve_error * 100))
names.append(name)
matchs.append(match_ratio * 100)
compacts.append(mcompact_error * 100)
curves.append(mcurve_error * 100)
data = {"method": names, "match": matchs, "compact": compacts, "curve": curves}
pd.DataFrame(data).to_excel(outPath, sheet_name='Sheet1', index=False)
import numpy as np
import glob
import tqdm
from PIL import Image
import cv2 as cv
import os
from sklearn.metrics import confusion_matrix,cohen_kappa_score
from skimage import io
from skimage import measure
from scipy import ndimage
from sklearn.metrics import f1_score
import gdalTools
def mean_iou(input, target, classes = 2):
""" compute the value of mean iou
:param input: 2d array, int, prediction
:param target: 2d array, int, ground truth
:param classes: int, the number of class
:return:
miou: float, the value of miou
"""
miou = 0
for i in range(classes):
intersection = np.logical_and(target == i, input == i)
# print(intersection.any())
union = np.logical_or(target == i, input == i)
temp = np.sum(intersection) / np.sum(union)
miou += temp
return miou/classes
def compute_iou(input, target, classes=1):
"""
compute the value of iou
:param input: 2d array, int, prediction
:param target: 2d array, int, ground truth
:param classes: int, the number of class
:return:
iou: float, the value of iou
"""
intersection = np.logical_and(target == classes, input == classes)
# print(intersection.any())
union = np.logical_or(target == classes, input == classes)
iou = np.sum(intersection) / np.sum(union)
return iou
def compute_f1(target, prediction):
"""
:param prediction: 2d array, int,
estimated targets as returned by a classifier
:param target: 2d array, int,
ground truth
:return:
f1: float
"""
prediction.tolist(), target.tolist()
img, target = np.array(prediction).flatten(), np.array(target).flatten()
f1 = f1_score(y_true=target, y_pred=img)
return f1
def compute_kappa(target, prediction):
"""
:param prediction: 2d array, int,
estimated targets as returned by a classifier
:param target: 2d array, int,
ground truth
:return:
kappa: float
"""
prediction.tolist(), target.tolist()
img, target = np.array(prediction).flatten(), np.array(target).flatten()
kappa = cohen_kappa_score(target, img)
return kappa
def compute_recall(gt, pred):
# 返回所有类别的召回率recall
matrix = confusion_matrix(y_true=np.array(gt).flatten(), y_pred=np.array(pred).flatten())
recall = np.diag(matrix) / matrix.sum(axis = 0)
return recall
def compute_acc(gt, pred):
matrix = confusion_matrix(y_true=np.array(gt).flatten(), y_pred=np.array(pred).flatten())
acc = np.diag(matrix).sum() / matrix.sum()
return acc
if __name__ == '__main__':
gtPath = r'D:\MyWorkSpace\paper\fishpond\data_evaluation\test2\poly.tif'
predictPath = r'D:\MyWorkSpace\paper\fishpond\data_evaluation\g2_otherNet\watershed_unetpp\poly.tif'
im_proj, im_geotrans, im_width, im_height, gt = gdalTools.read_img(gtPath)
im_proj, im_geotrans, im_width, im_height, pred = gdalTools.read_img(predictPath)
gt = np.where(gt > 0, 1, 0)
pred = np.where(pred > 0, 1, 0)
iou = compute_iou(gt, pred)
f1 = compute_f1(gt, pred)
kappa = compute_kappa(gt, pred)
recall = compute_recall(gt, pred)
acc = compute_acc(gt, pred)
print(f'acc:{acc}, iou:{iou}, f1:{f1}, kappa:{kappa}, recall:{recall}')
基于边缘的指标
参考A Benchmark Dataset and Evaluation Methodology for Video Object Segmentation ,DeepStrip: High Resolution Boundary Refinement
import numpy as np
import math
""" Utilities for computing, reading and saving benchmark evaluation."""
def db_eval_boundary(foreground_mask,gt_mask,bound_th=0.008):
"""
Compute mean,recall and decay from per-frame evaluation.
Calculates precision/recall for boundaries between foreground_mask and
gt_mask using morphological operators to speed it up.
Arguments:
foreground_mask (ndarray): binary segmentation image.
gt_mask (ndarray): binary annotated image.
Returns:
F (float): boundaries F-measure
P (float): boundaries precision
R (float): boundaries recall
"""
assert np.atleast_3d(foreground_mask).shape[2] == 1
bound_pix = bound_th if bound_th >= 1 else \
np.ceil(bound_th*np.linalg.norm(foreground_mask.shape))
# Get the pixel boundaries of both masks
fg_boundary = seg2bmap(foreground_mask);
gt_boundary = seg2bmap(gt_mask);
from skimage.morphology import binary_dilation,disk
fg_dil = binary_dilation(fg_boundary,disk(bound_pix))
gt_dil = binary_dilation(gt_boundary,disk(bound_pix))
# Get the intersection
gt_match = gt_boundary * fg_dil
fg_match = fg_boundary * gt_dil
# Area of the intersection
n_fg = np.sum(fg_boundary)
n_gt = np.sum(gt_boundary)
#% Compute precision and recall
if n_fg == 0 and n_gt > 0:
precision = 1
recall = 0
elif n_fg > 0 and n_gt == 0:
precision = 0
recall = 1
elif n_fg == 0 and n_gt == 0:
precision = 1
recall = 1
else:
precision = np.sum(fg_match)/float(n_fg)
recall = np.sum(gt_match)/float(n_gt)
# Compute F measure
if precision + recall == 0:
F = 0
else:
F = 2*precision*recall/(precision+recall);
return F
def seg2bmap(seg,width=None,height=None):
"""
From a segmentation, compute a binary boundary map with 1 pixel wide
boundaries. The boundary pixels are offset by 1/2 pixel towards the
origin from the actual segment boundary.
Arguments:
seg : Segments labeled from 1..k.
width : Width of desired bmap |